Intelligenza Artificiale, sai davvero cos’è?
Si fa presto a dire Intelligenza Artificiale, soprattutto di questi tempi: il tema è entrato a far parte di ogni strategia di business e marketing, con un boom tale da essere diventato quasi una moda, un’ossessione in cui a volte ci si potrebbe dimenticare che le tecnologie devono essere al servizio di una strategia aziendale, e non il contrario. È importante quindi capire di cosa parliamo quando incontriamo i termini Artificial Intelligence, Machine Learning e Deep Learning, quali siano i loro valori aggiunti, quali i loro limiti e potenzialità.
Il termine Artificial Intelligence nasce nei primi anni ‘50, quando al Dartmouth College di Hanover nel New Hampshire viene organizzato un workshop per chiarire e sviluppare idee sui temi delle macchine pensanti, concetto sviluppatosi in quegli anni con varie denominazioni e sfaccettature, ma definito nei suoi termini essenziali e moderni dal genio di Alan Turing, che con il suo paper “Computing Machinery and Intelligence” [1] chiarì come la domanda “le macchine sono in grado di pensare?” potesse essere trasformata in “le macchine sono in grado di agire come se pensassero?”. È in quest’ottica che ricaviamo la definizione di Intelligenza Artificiale, ovvero come quella di tutte le metodologie e tecniche che consentono la progettazione di sistemi hardware e programmi software capaci di fornire all’elaboratore elettronico prestazioni che, all’osservatore comune, sembrerebbero essere di pertinenza esclusiva dell’intelligenza umana.
Ideare un’intelligenza artificiale, quindi, non implica necessariamente l’impiego di tecniche di machine learning.
Deep Blue, il supercomputer ideato da IBM per battere il campione di scacchi Garry Kasparov e dimostrare la possibilità per un calcolatore di eguagliare l’intelligenza umana nel gioco, non faceva uso di alcuna di quelle che oggi definiremmo soluzioni di machine learning. È invece la complessità del problema da risolvere, e l’impressione che la macchina sviluppi una sorta di pensiero a riguardo che qualificano le caratteristiche essenziali per parlare di Artificial Intelligence.
Lo sviluppo di assistenti virtuali, il cuore dell’attività di Responsa, è imprescindibilmente collegato a quello di Intelligenza Artificiale, al punto che la tematica stessa viene posta come uno dei principali temi di dibattito già nel documento con cui McCarthy, Minsky, Rochester e Shannon proposero il Darthmouth Summer Research Project On Artificial Intelligence del 1956 [2].
How Can a Computer be Programmed to Use a Language.
It may be speculated that a large part of human thought consists of manipulating words according to rules of reasoning and rules of conjecture. From this point of view, forming a generalization consists of admitting a new word and some rules whereby sentences containing it imply and are implied by others. This idea has never been precisely formulated nor have examples been worked out.
Ma se Intelligenza Artificiale e Natural Language Processing hanno radici così remote, perchè oggi queste tematiche sono continuamente argomento di dibattito e sviluppo?
Nonostante un certo entusiasmo iniziale, che portò anche alla nascita delle teorie alla base delle attuali tecniche di deep learning, una serie di concause portò ad un generale pessimismo sulle possibilità effettive di questi metodi, i progetti di ricerca incontrarono maggiore difficoltà nel reperimento dei finanziamenti necessari, e l’interesse si fece mite e discontinuo [3]. Le maggiori possibilità computazionali e la nuova cultura dei Big Data portarono nei primi anni 2000 ad una nuova esplosione del tema, con un particolare focus su machine learning e deep learning.
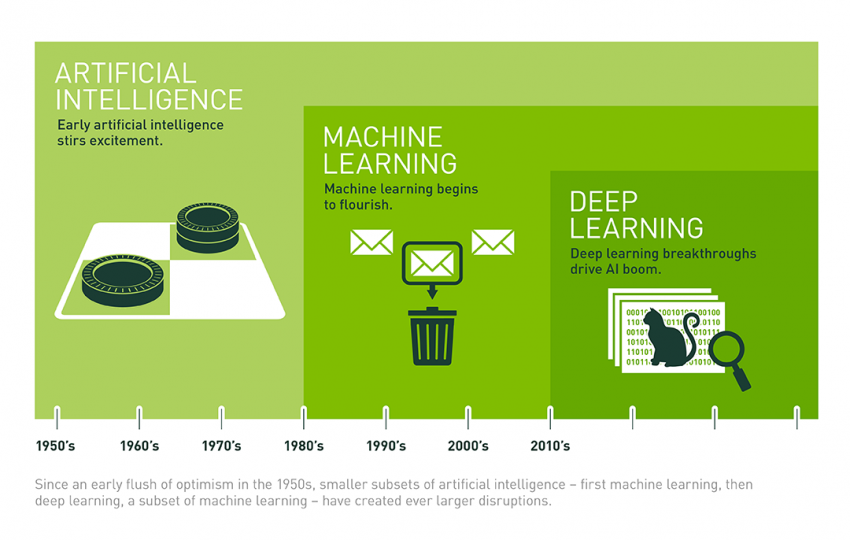
Machine Learning e Deep Learning.
Pur essendo il dominio di un problema (non solo il suo metodo di risoluzione) a definire l’ambito dell’Intelligenza Artificiale, è chiaro come dovendo affrontare questioni complesse come quella della comprensione del linguaggio naturale o dello sviluppo di agenti conversazionali, diventi estremamente complicato riuscire a prevedere l’immenso numero di passi logici per sviluppare un algoritmo in grado di coprire ogni possibile casistica presentata dal problema, mentre sarebbe molto più semplice, come del resto avviene anche per l’uomo, se fosse la macchina, opportunamente posta di fronte ad una serie di casi d’esempio, ad “imparare” autonomamente la soluzione del problema.
Quando parliamo di machine learning intendiamo proprio questo: un ampio spettro di modelli e algoritmi matematico-statistici pensati per l’ottimizzazione del risultato atteso di un input. Tra questi, le reti neurali, sofisticate architetture basate sulla simulazione dello stesso meccanismo che regola l’attivazione delle cellule cerebrali, spiccano per la loro versatilità e profonda capacità di astrazione ed apprendimento (da cui il termine deep learning – apprendimento profondo).
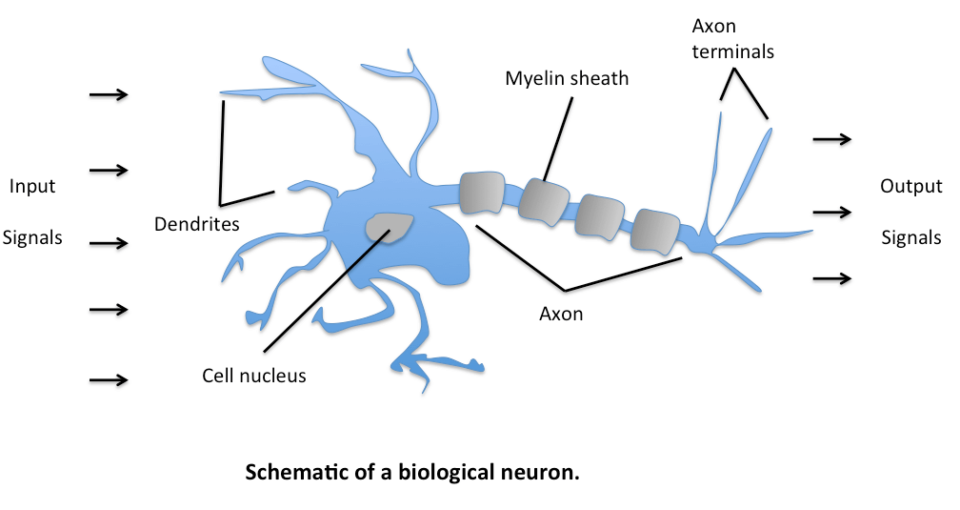
La possibilità di accedere on premise a soluzioni di computing ad alte prestazioni ha democratizzato l’accesso a queste tecnologie, rendendole estremamente popolari ed accelerarandone il processo di sviluppo. Il forte exploit del settore, inoltre, accompagnato dallo sviluppo di acceleratori hardware dedicati (GPU, TPU), ha dimostrato come una rete neurale sia in grado di approssimare, potenzialmente, qualsiasi funzione, e quindi portare, in teoria, alla risoluzione di qualsiasi problematica.
Anche per questo motivo l’impatto dei Tech Giants, a livello di dibattito sociale, filosofico e legislativo, è stato ripetutamente portato all’attenzione dei media in questi anni, in quanto i grandi titani tecnologici si sono trovati nella condizione di possedere l’intera complessità dei dati raccolti in una mano e la possibilità di comprenderla e manipolarla nell’altra [4].
Sebbene si sia ancora lontani da quella che nel settore viene definita Artificial General Intelligence, ovvero una generica ed autonoma capacità di pensiero da parte di una macchina, è indubbio come l’utilizzo di queste tecniche stia aprendo nuovi orizzonti e portando lo sviluppo di prodotti e servizi ad un nuovo livello.
In Responsa abbiamo scelto di concentrarci sulle sfide del linguaggio per aiutare le aziende a costruire la propria base di conoscenza, strutturarla, e trasmetterla ai propri clienti e dipendenti nel modo più naturale possibile, quello del dialogo. In questo scambio perfetto, ogni richiesta diventa una possibilità di miglioramento della richiesta successiva. Da anni, collezioniamo conversazioni e conoscenza, problemi e soluzioni. Così com’è per noi, questa preziosa fonte d’informazione viene assimilata anche dai nostri modelli di machine learning che, imparando dai nuovi esempi e dai propri errori, incrementano giorno dopo giorno la loro accuratezza nella comprensione delle richieste e nella qualità delle risposte fornite. Col tempo, abbiamo imparato a trasformare l’informazione in risposte, sperimentando le nuove possibilità della computer vision per assimilare la conoscenza anche da fonti non strutturate, come la documentazione delle aziende, o i loro ticket. Esperti di linguistica lavorano ogni giorno a stretto contatto con i nostri sviluppatori, in un meccanismo sinergico di scambio e ricerca di nuove soluzioni, integrazione di flussi aziendali e question answering, affinché diventi sempre più naturale lo scambio tra l’intelligenza umana e quella artificiale.


Riferimenti.
[1] A. M. Turing, Computing Machinery and Intelligence, 1950, https://www.csee.umbc.edu/courses/471/papers/turing.pdf
[2] McCarthy, Minsky, Rochester, Shannon, A proposal for the Dartmouth Summer Research Project on Artificial Intelligence, 1955, http://raysolomonoff.com/dartmouth/boxa/dart564props.pdf
[3] Wikipedia, AI Winter, 2020.06.22, https://en.wikipedia.org/wiki/AI_winter
[4] visualcapitalist.com, Here’s What the Big Tech Companies Know About You, 2020.06.22, https://2oqz471sa19h3vbwa53m33yj-wpengine.netdna-ssl.com/wp-content/uploads/2018/11/data-tech-companies.png

![[4]](https://2oqz471sa19h3vbwa53m33yj-wpengine.netdna-ssl.com/wp-content/uploads/2018/11/data-tech-companies.png){kind=link}