Embeddings: nella mente di una rete neurale
“Embedding” è un termine molto comune nel campo dell’intelligenza artificiale ed un concetto decisivo per il funzionamento dei modelli di deep learning.
Una versione estremamente semplificata della concezione matematica di “embedding” (dall’inglese embed => integrare, includere) è quella di una struttura in grado di contenere in sè l’informazione presente in un’altra struttura. Per semplificare ulteriormente questa idea pensiamo al DNA: esso è una particolare combinazione di valori che permette la rappresentazione (o la ricostituzione) dell’estrema complessità dell’informazione vitale immersa in essa.
Rappresentare un testo in forma numerica
Per capire per quale motivo il concetto di embedding sia così importante facciamo un passo indietro: i modelli di machine learning necessitano di input numerici. Non è possibile effettuare calcoli su un testo così come viene interpretato da noi, è necessario infatti individuare una strategia per trasformare tale input testuale in una serie significativa di valori numerici (un vettore, matrice, o tensore), in un processo normalmente definito come “vettorizzazione”. Questa fase è cruciale, in quanto il rischio di perdere informazioni vitali durante questa trasformazione è molto alto. L’enorme quantità di sfumature trasportate da una parola (o più in generale, da un testo) rende questo passaggio tutt’altro che banale.

Un primo approccio potrebbe essere quella di creare un grande vocabolario, contenente tutti o la maggior parte dei termini che incontreremo, ed utilizzarlo per rappresentare ogni parola come una lunga serie di “zero” interrotta dal valore “uno” all’occorrenza dell’indice di tale termine all’interno del vocabolario creato (one hot encoding).

One Hot Encoding
Vediamo inoltre come sia possibile costruire dei vettori che rappresentino un corpus testuale: nell’esempio riportato abbiamo sommato le frequenze delle parole all’interno della frase, ma esistono diverse soluzioni applicabili: avremmo potuto concatenare i diversi vettori-parola tra loro, utilizzare il valore di particolari metriche (la più comune è la TermFrequency-InverseDocumentFrequency), oppure sviluppare dei modelli specializzati nell’estrazione di informazioni significative in forma vettoriale.
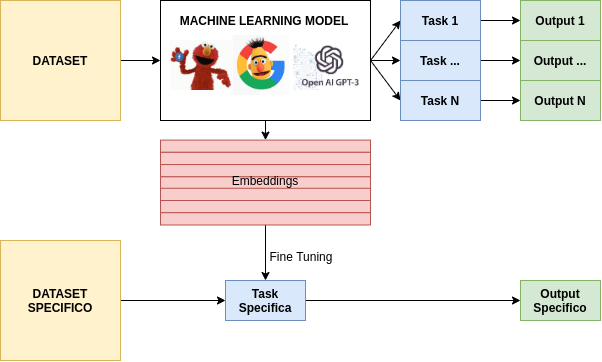
Embeddings
I metodi basati su indici posizionali possono essere efficaci, ma piuttosto rudimentali. Si è quindi gradualmente puntato su rappresentazioni più sofisticate, che avessero come obbiettivo l’astrazione del significato in vettori numerici più significativi per i quali termini affini avessero simili valori. Queste possibilità hanno aperto nuovi scenari [4], portando a calcoli più precisi della similarità semantica, dell’“attenzione”[5], ed una maggiore accuratezza dei modelli classificazione e delle principali task legate all’NLP [6].

I modi per calcolare i vettori di embedding sono molteplici, ma sono accomunati dal fornire alla rete neurale alcune task da risolvere: data una parola indicare lemmi che appaiono in un contesto simile, e viceversa (CBOW/Skipgram), mascherare parzialmente alcuni token di una frase e richiedere alla rete di completare i tasselli mancanti (Masked LM), capire se due frasi siano conseguenti tra loro (NextSentencePrediction), oppure risolvere un problema specifico (per ottenere embeddings meno generici e più specializzati).
Possiamo pensare a questi valori numerici calcolati dalla rete neurale come le caratteristiche astratte che il modello ha ricavato dagli esempi ricevuti. Ad esempio, un valore potrebbe guidare la rete nella comprensione dei singolari/plurali, del genere, oppure altre caratteristiche, ma è importante sottolineare che la natura di tali caratteristiche può essere compresa solo dal modello, non può essere derivata né ricondotta a quelle stesse caratteristiche che noi, come esseri umani, utilizziamo per la comprensione di un testo.
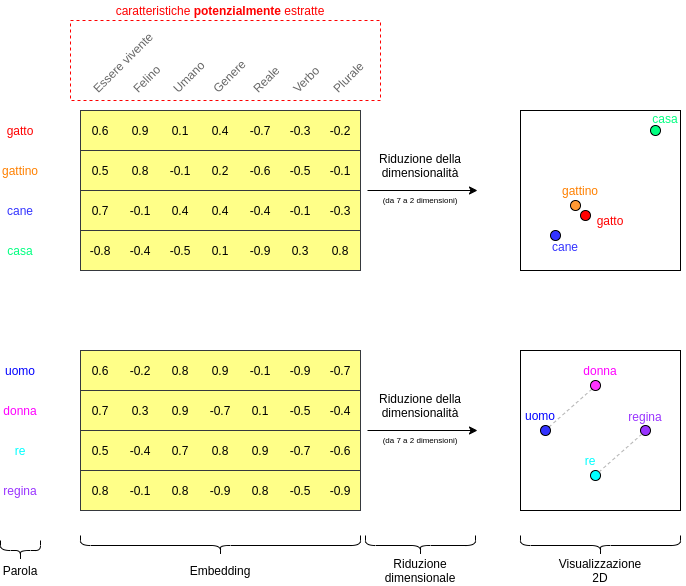
Per riassumere, quando sentiamo parlare di embeddings intendiamo la mappa di valori che un modello ha estratto dai contenuti sul quale è stato allenato. Responsa utilizza un mix di strategie per l’estrazione di tali valori ed il suo impiego in diversi ambiti, come quello di classificazione di intenti, entità, smalltalks, calcolo della similarità semantica e molto altro.
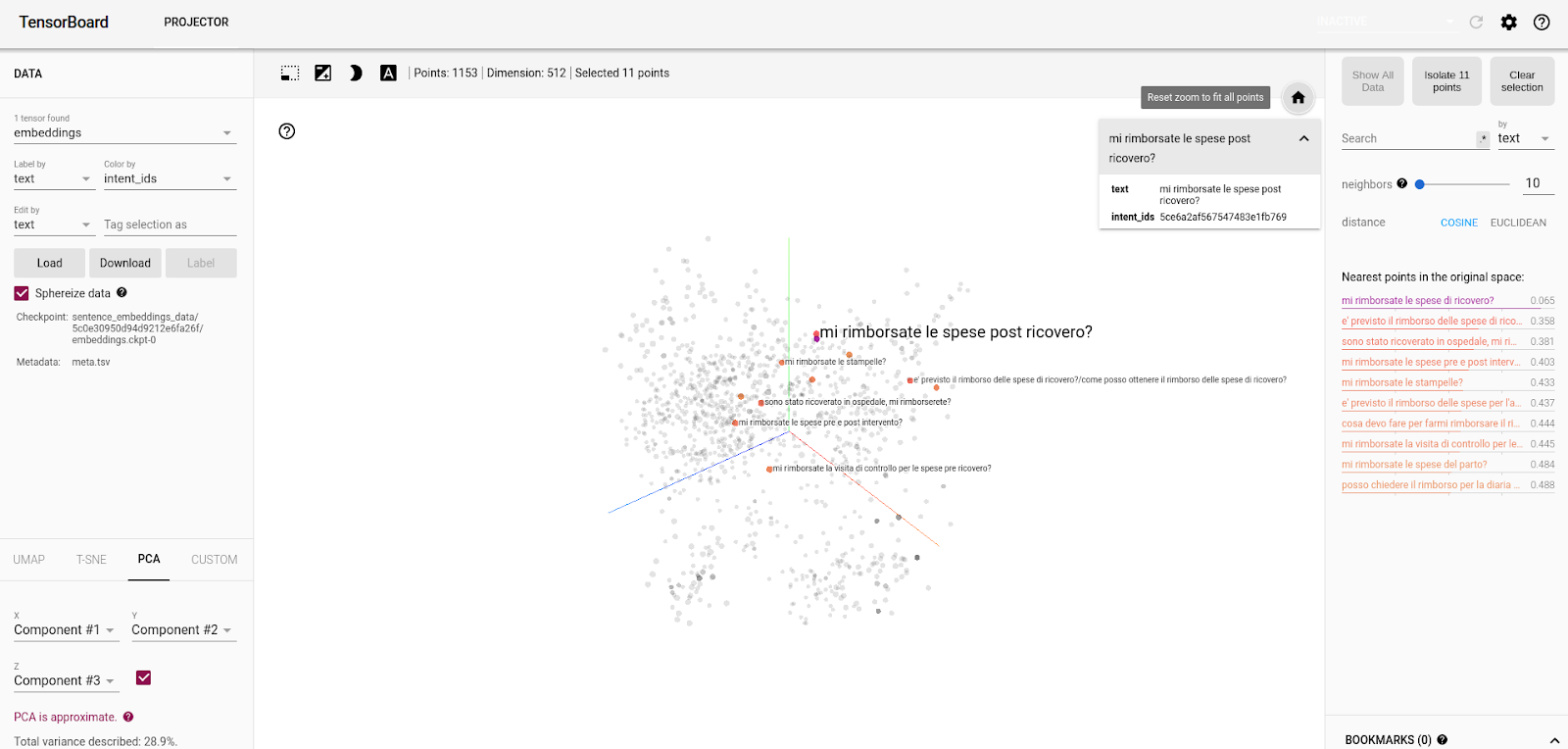
Riferimenti:
[1] Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova – BERT: Pre-training of Deep Bidirectional Transformers for
Language Understanding – 2019 – https://arxiv.org/pdf/1810.04805.pdf
[2] Stefano Frassetto – You Should Try The New TensorFlow Text Vectorization Layer – 2020 – https://towardsdatascience.com/you-should-try-the-new-tensorflows-textvectorization-layer-a80b3c6b00ee
[3] TensorFlow Embeddings Projector – https://projector.tensorflow.org/
[4] Sebastian Ruder – NLP’s ImageNet moment has arrived – 2018 – https://ruder.io/nlp-imagenet/
[5] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin – Attention Is All You Need – 2017 – https://arxiv.org/pdf/1706.03762.pdf
[6] – GLUE Benchmark – https://gluebenchmark.com/tasks